class: center, middle ### Getting to Continuous Deployment  --- class: center, middle ## Getting to Continuous Deployment  Lee Johnson (CPAN: LEEJO / github: leejo) ??? --- class: center, middle  ??? A bit about PayProp ZA, UK, CA, US Slowly opening in CA and US --- class: center, middle  --- ## Continuous Deployment? "Continuous deployment (CD) is a strategy in software development where code changes to an application are released automatically into the production environment." -- Simple! ??? This talk is more about all of the things you need in place before you even consider CD, it's not a talk about how to setup and configure all of the CD like things I might show some of that at the end if we have time however Small caveat - talk was written as an internal presentation that I've adapted for a wider audience. --- ## Questions? -- * Jot them down and if we have time at the end we can cover them -- * Jot down the point number in the bottom right corner of the slide as well --- ## A Brief Introduction [to me] -- * Backend/API developer ??? Perl, Python, Ruby, Bash, C (but rusty), etc -- * Largely in the "payments" space ??? often backend bank integration kind of stuff -- * I've been doing this for twenty years 😳 ??? but only worked for three companies in that time so have seen tech stacks grow -- * More in a site reliability engineering [SRE] role these days -- * Often been involved on the deployment side of things ??? Including 3am starts - remember those? wrote quite a few tools around this in current and previous jobs -- * Pragmatist, not an idealist --- ## Quixotism? */kiːˈhoʊtɪzəm/* ??? On that last point -- * "Impracticality in pursuit of ideals... -- * "... especially those ideals manifested by rash, lofty and romantic ideas" -- * "... It also serves to describe an idealism without regard to practicality" -- * Need to consider the practicality of getting to Continuous Deployment --- ## Practicality (Technical)? -- * What state is your current deployment process in? -- * Can you deploy all/some/no changes without a maintenance windows? ??? how often and how long are those maintenance windows? -- * Do you need to babysit the deployment process? -- * Run commands/restart processes manually? -- * Apply DB updates manually? -- * How's your monitoring? -- * How quickly do you know PROD is having issues? -- * Who gets alerted to that? --- ## Practicality (Human Side)? -- * I don't want to be woken up because someone merged something to `main` at X o'clock CET ??? with distributed teams/devs those merges can happen -- * I like to have my weekends free of work stuff -- * Friday evening is part of my weekend... -- * FAANG's site reliability engineering [SRE] teams are probably bigger than your entire IT department ??? FAANG: Facebook (now Meta Platforms), Amazon, Apple, Netflix and Google -- * By an order of magnitude -- * They effectively have 24/7 SRE coverage ??? you probably do not --- ## Practicality (Human Side)? * PROD will have issues even when you make no changes -- * Especially in "cloud" environments ??? "failure modes in cloud computing" is a entire other talk i've been collecting these so might give that talk one day -- * So by association CD can never be risk free -- * "This change can't possibly have any impact" -- * I disagree -- * You're going to lose an evening or weekend at some point even with no deployments -- * So reduce the chance of that happening ??? when are the most PROD outages? when devs are in the office deploying changes --- ## Our Infrastructure (PROD) -- Long before I joined (early years, mid 2000s) -- * A single server sat in an office somewhere in Stellenbosch (South Africa, Western Cape) ??? pretty easy to deploy to that root on everything as well --- ## Our Infrastructure (PROD) When I joined (mid 2013): 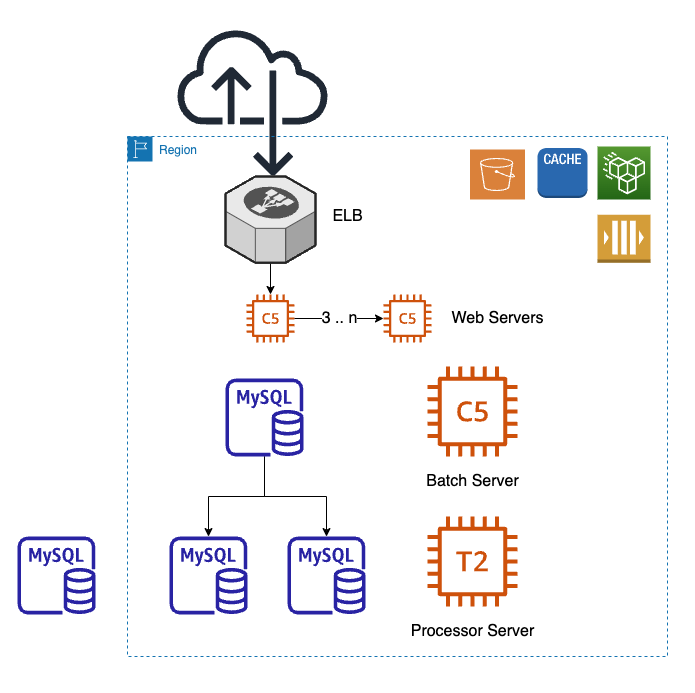 ??? There's a tonne of stuff i haven't put in here the bits in orange are the ones of concern: what we deploy code to --- ## Our Infrastructure (PROD) Current situation (mid 2023) 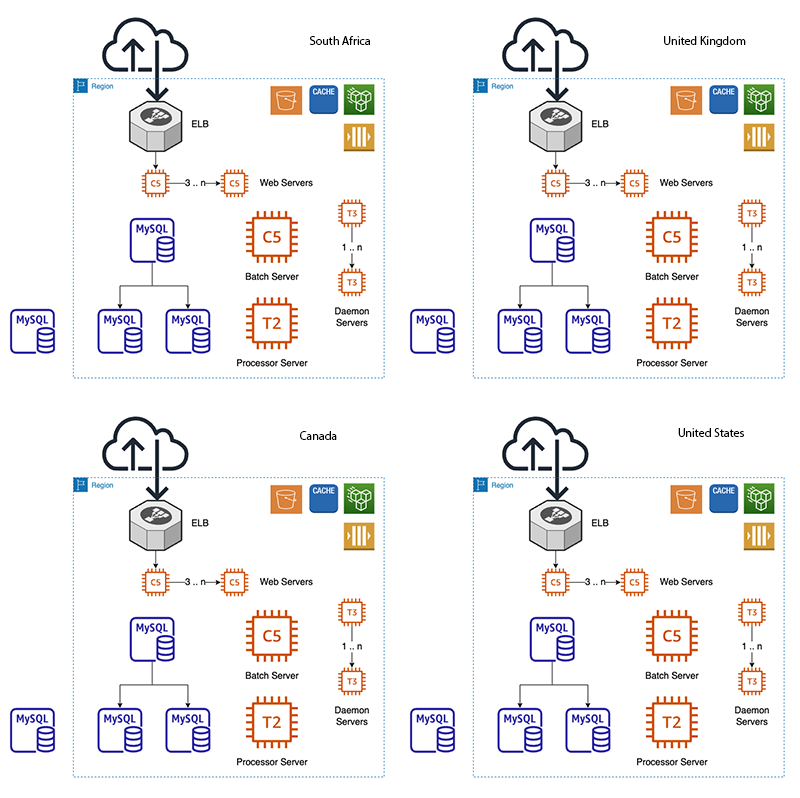 ??? also added daemon servers --- ## Our Infrastructure (PROD) -- * Deploy to: web servers, batch server, daemon server(s) -- * Autoscaling (Web and Daemon servers) -- * We handle payments and reconciliation for the rental industry -- * Quietest case: c. 20 servers to deploy code to * Busiest case (start/end of month): *at least* 100 servers to deploy code to * Spread across 4 different AWS regions ??? I consider this large enough to mean automated deployment is necessary, but small enough where automated deployment can cause problems if you have thousands of severs you can do a rolling release and stop then rollback when you identify problems if you only have dozens or hundreds then you may well have finished rolling out a problematic deployment before you realise it is problematic -- * Minimum threshold for automated deployment is probably 1 server anyway --- ## Our Infrastructure (PROD) -- * Deployment started as tarballs ??? When it was just one or two servers -- * Then bash scripts ??? When we were in one region -- * Now a Perl script that is configuration driven ??? When i started to get annoyed by the bash scripts and we added more regions -- * Future aim is containerisation so images/containers/whatever ??? At which point the toolchain will need refactoring/replacing --- ## Getting To Continuous Deployment? -- * What are the things you need in place before you even *think* about CD? -- * How do they help? -- * How do they hinder? --- ## You Need: Consistency Through Your Environments -- * Same version of Perl (currently 5.32 for us) -- * With the same versions of the libraries -- * Same version of the Operating System -- * With the same versions of critical dependencies ??? e.g. PDF generation -- * This goes for DEV all the way through to PROD -- * Write once run everywhere is nice in theory -- * Until you need to run `strace` to figure out a regression --- ## You Need: Comprehensive Automated Testing -- * Goes without saying? ??? Yet i still see significant changes that lack test coverage ramble about this a bit... legacy? might not have tests third parties? difficult, need emulators, etc -- * Adding tests has a large negative impact on velocity -- * At least in the short to medium term -- * It should become a large positive impact in the long term -- * If you do it right -- * There's no such thing as a one line or one character change -- * Unless that change is only in the test --- ## You Need: Continuous Integration (CI) -- * You need tests for this (see previous slide) -- * CI needs its own infrastructure -- * How easily can you build that up and tear it down? -- * How close does it represent PROD architecture? ??? a single box and filesystem is not like PROD firewalls? etc? -- * Failures in the CI pipeline are sometimes failures in the toolchain -- * But false negatives (failures) are better than false positives (passes) in CI ??? A CI suite falsely passing is obviously bad --- ## You Need: A Review and Quality Assurance [QA] Process -- * Anything that can be automated here should be in the test stage -- * Linting, etc -- * Formalise the review process and apply to all merge requests -- * With good judgement to allow exceptions --- ## You Need: Staging -- * For the bigger changes -- * Part of the review process -- * For UAT from clients -- * This may inform the release process if it's not a trivial set of changes --- ## You Need: An Internal Toolchain -- * Deployment scripts -- * Schema migrations and updates -- * Repo management (if big enough) -- * Monitoring -- * Alerting --- ## You Need: An "External" Toolchain -- * You will rely on tools built outside your company -- * Choose wisely, couple loosely -- * Gitlab -- * AWS ??? We even use AWS to autoscale our CI server, which is neat -- * Monitoring * Alerting --- ## You Need: A Rollback Feature -- * Built into the deployment process -- * We tag every release to each region -- * We annotate monitoring dashboards with releases -- * We can rollback to previous releases trivially -- * If you do release frequently this is (in theory) easier --- ## You Need: To Think About The Database / Complex Deployments? -- * Feature flags -- * Still have to babysit significant schema changes -- * Write them in a "no downtime" approach if possible -- * Backwards and forwards compatible ??? and then remove the backwards compatible parts after rolling forwards -- * Deploy them during quiet periods of the month? --- ## You Need: Checking Once Changes Hit Production -- * How do the original developers *know* it has been deployed? ??? we send notifications to Slack and email -- * How do you verify those changes? ??? internal accounts / test users clearly --- ## You Need: Continuously Deploy All The Internal Things First -- * A good proof of concept -- * Internal tools *probably* don't affect the bottom line. -- * Internal tools breaking for a short time isn't critical * At least not immediately, that is to say no customer impact * And you *probably* don't have to fix them out of office hours ??? If it's internally facing only you can probably use CD and not worry about the short-term consequences... maybe? -- * Encourages development of the toolchain --- ## How Far Have *We* Got? -- We have full CD on internal tools: -- * Translation manager * DB extract/backup scripts * The deployment scripts themselves (meta!) ??? describe each one -- * We have Semi CD elsewhere --- ## Semi-Continuous Deployment? * One click "deploy to everywhere" is a nice compromise? -- 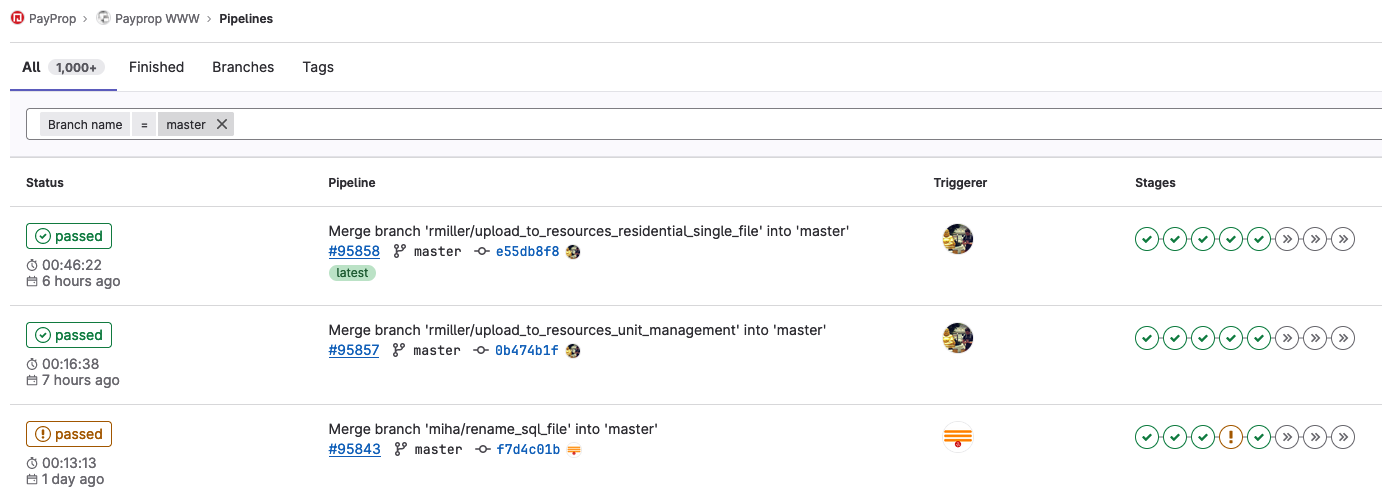 --- ## Semi-Continuous Deployment? * One click "deploy to everywhere" is a nice compromise? 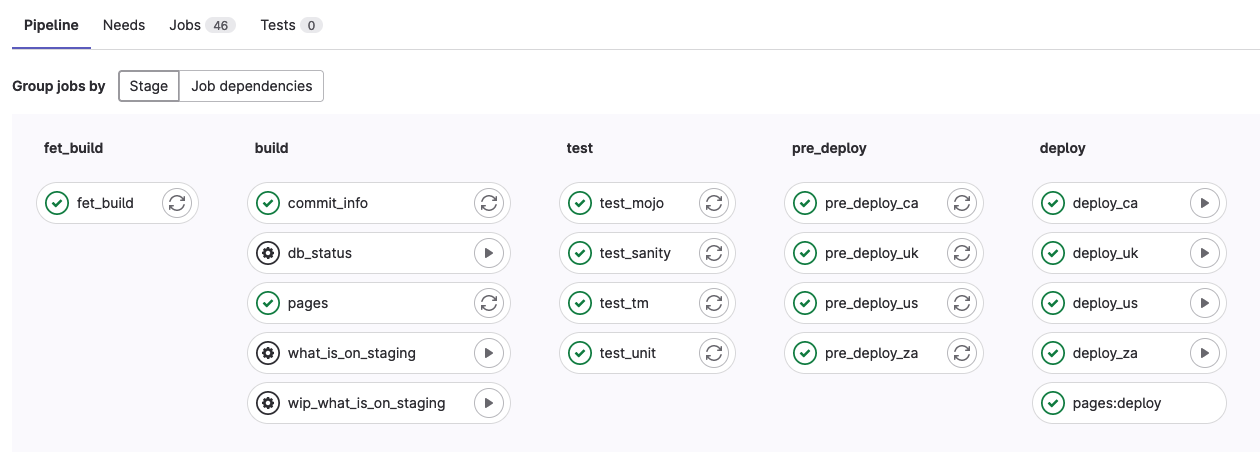 --- ## Semi-Continuous Deployment? * One click "deploy to everywhere" is a nice compromise? 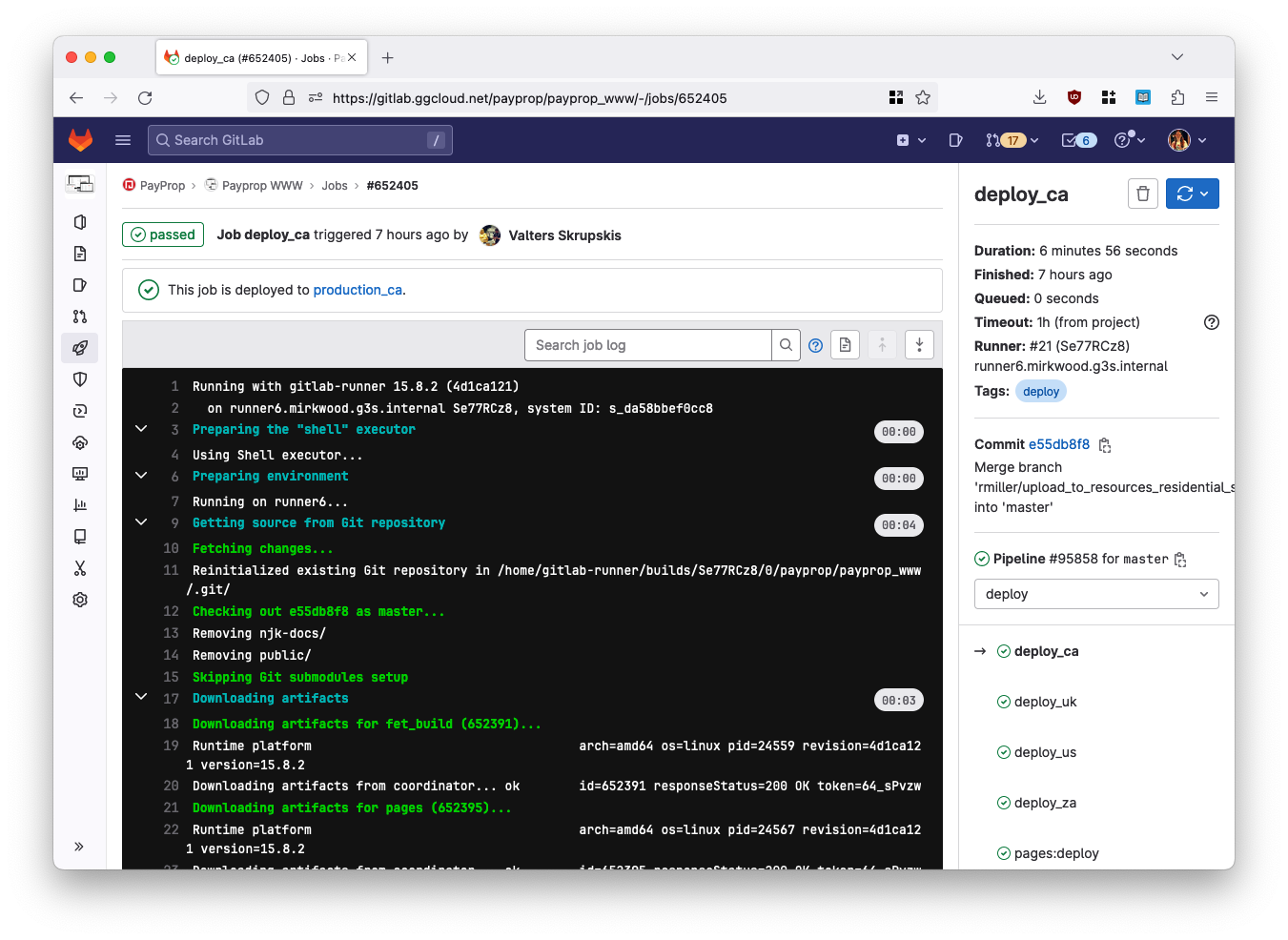 --- ## Questions or Bonus "Slides" (i.e. Demo)? ??? bonus slides show: * pipelines * gitlab CI * gitlab CD * grafana dashboards with annotations * slack channel with deployment info --- ## Questions?